Validation Benchmark Update
TL;DR: schema implementation is fixed & validation-benchmark report is now hosted on GitHub Pages.
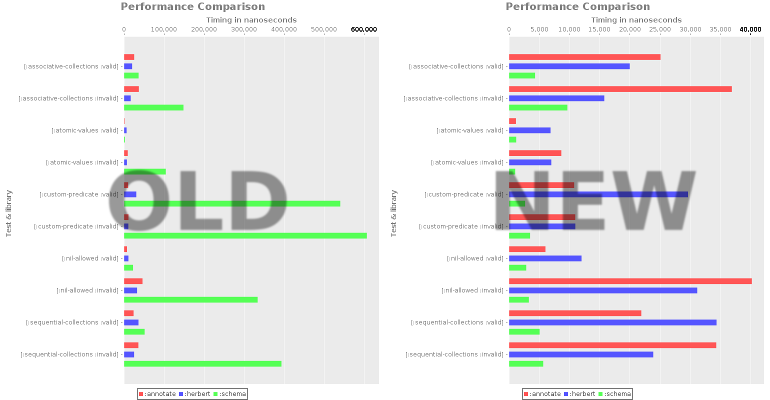
Jason Wolfe for fixed schema implementation. This not only got rid of huge discrepancies (50x difference), it made schema the fastest validation library (best, except in one benchmark).
I am curious as to why schema is roughly 5 times faster than annotate & herbert. As far as I can understand they are all using pre-compiled checkers. Is is because schema is tuned carefully for performance? Or could it be that my code is not benchmarking what I think it is benchmarking? If you haven’t, I would appreciate if you can take a look at the code.
Secondly you can view the latest benchmark result at muhuk.github.io/validation-benchmark. If you run the benchmark locally, the report will be in target/report directory. The page is still very crude but the data is there. Pull requests that improve the report are welcome.
I have also uploaded the latest raw results. I am thinking of embedding this data into the report page in the future.
If you have any questions, suggestions or corrections feel free to drop me a line.