Performance Cost of Runtime Type Checking
Type systems should be considered design tools rather than safety wheels of a programming language or laser guided missiles for software defects. Compile time type checking can find type related defects, but not value related ones. Values are not known yet.
UPDATE: Performance Comparison of Annotate, Herbert & Schema
UPDATE: Benchmarking Clojure Validation Libraries
For example, we can check that some argument is of List, but we cannot check if it’s an empty list[1]:
{- Calling head on an empty list result with a runtime error. -}
head []
-- => *Exception: Prelude.head: empty list
{- We must make a runtime check to make sure: -}
maybeHead :: [a] -> Maybe a -- Compile time
maybeHead [] = Nothing -- Runtime
maybeHead (x:_) = Just x -- Also runtime, at this point we know the value of x
maybeHead []
-- => Nothing
maybeHead [1]
-- => Just 1
maybeHead [2, 3]
-- => Just 2
{- See <https://hackage.haskell.org/package/safe> for more info -}
What we do above, in the line commented with “Runtime” and the one below, is checking the values. Because list cardinality is not part of Haskell’s type system. As far as type checker is concerned, a list is a list. There is no difference between an empty list and a list that contains something.
What I am trying to get at is static type checking has its limitations. Dynamic languages can’t take advantage of this very useful but limited tool[2]. But they can still perform run time type checking. Since values are also available, more precise constraints can be defined. This is of course nothing but validation, just with fancier names.
I am working on a large(ish) Clojure codebase. It has very good unit test coverage and makes use of Clojure’s built-in contracts[3]. With no static type checking, when a function’s signature changes its mocks will happily work assuming the old signature is still valid. Any other function that calls our modified function therefore will be broken. Contracts are useful for this specific reason. But they are not always efficient:
;; This is the same as above. The precondition code is bigger
;; than the actual code. Imagine validating a more complex type
;; than a sequential collection.
(defn head [xs]
{:pre [(and (sequential? xs)
(seq xs))]}
(first xs))
So I started looking into libraries that would make this easier. There are two slightly different use cases for validation:
- Validating external input. Trust, but verify. No, actually just verify. These should be always on.
- Validating inputs and outputs of code units as well as intermediary values. Assuming valid inputs, these serve to ensure the correctness of our code. We should be able to disable these, especially in production.
I am especially interested in the performance impact for the second case.
Method
Initially I have chosen two libraries that provide annotating functions but later realized a specialized defn can be written for any validation library and these annotations are not unintrusive like core.typed annotations. Also having to use a special defn is not composable. If there is another library that adds, say instrumentation, via a defn like macro, you have to choose between validation and that. So I should admit my sampling was not quite fair and my method was not necessarily best way to approach this. Perhaps lack of a special defn form should be considered as a feature.
Benchmark contains three functions. A simple function that does next to nothing:
(defn boolean? [v]
(or (true? v)
(false? v)))
A function that returns a lazy sequence, calling itself and triggering validation multiple times:
;; From http://rosettacode.org/wiki/Sorting_algorithms/Quicksort#Clojure
(defn qsort [[pivot & xs]]
(when pivot
(let [smaller #(< % pivot)]
(lazy-cat (qsort (filter smaller xs))
[pivot]
(qsort (remove smaller xs))))))
And a function that contains a loop, supposedly doing more work but triggering validation once:
(defn rle [in]
(if (empty? in)
()
(loop [cnt 0
curr (first in)
[x & xs] in
out ()]
(if (nil? x)
(reverse (conj out [cnt curr]))
(if (= x curr)
(recur (inc cnt) x xs out)
(recur 1 x xs (conj out [cnt curr])))))))
Although these benchmarks are about the second use case for validation I have used always on versions of function annotations.
I should also mention that the benchmarks call the functions only with valid inputs. Again this is related to the second use case, we are assuming valid (external) inputs and checking the correctness of our code.
Finally performance is not the most important aspect of validation. In my opinion performance comes behind readability in this context. Especially since the plan is to disable these checks in production. So, please read too much into the numbers.
The Data
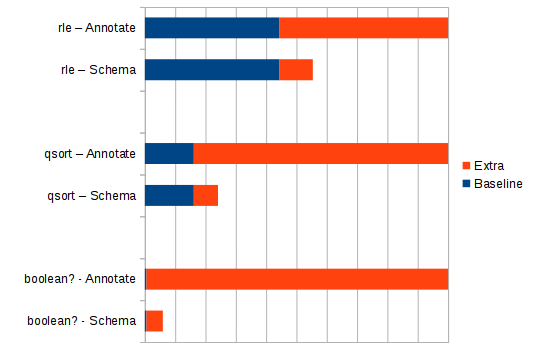
The timings below are in nanoseconds per call.
| Function | Placebo | Schema | Annotate |
|---|---|---|---|
| boolean? | 113 | 1247 | 21013 |
| qsort | 3177327 | 4748554 | 19675893 |
| rle | 197496 | 246292 | 444575 |
The graph below shows normalized timings. Blue areas indicate run time without validation and the red areas are additional time taken for validation.
Conclusion
As I mentioned above, benchmarks based on validating values not just function annotations would make more sense.
Schema seems to be a lot faster than Annotate. I wonder why is there such a big difference. Could it be that my setup is not correct? Or is there some secret behind the performance difference.
I said performance is not the most important aspect of validation, but it still matters. Both libraries have acceptable performance with the exception of Annotate’s qsort timings. I will prepare another benchmark with more alternatives. In the meantime, let me know if there are any errors on my part or things that can be improved.
| [1] | Idris and some other languages have more expressive type systems that allows this. |
| [2] | Actually they can. Optional type systems like core.typed provide static type checking with (arguably) more effort than just using a statically typed language. My point above is that type checking is not built into dynamic languages. Obviously. |
| [3] | See :pre & :post |
If you have any questions, suggestions or corrections feel free to drop me a line.