Benchmarking Clojure Validation Libraries
Three weeks ago I have written about my interest in validation libraries. There were some benchmark results in that post that I was not too happy with. I am working on a new, more comprehensive benchmark.
UPDATE: Performance Comparison of Annotate, Herbert & Schema
I wanted to build a better benchmark, one that doesn’t only measure defn variants. To be honest I try to avoid defn variants. Actually any def form that add a new trick to existing ones[1]. Because, like I have written, they do not compose:
Initially I have chosen two libraries that provide annotating functions but later realized a specialized defn can be written for any validation library and these annotations are not unintrusive like core.typed annotations. Also having to use a special defn is not composable. If there is another library that adds, say instrumentation, via a defn like macro, you have to choose between validation and that. So I should admit my sampling was not quite fair and my method was not necessarily best way to approach this. Perhaps lack of a special defn form should be considered as a feature.
Two use cases I have mentioned in the previous post are also worth repeating:
- Validating external input. Trust, but verify. No, actually just verify. These should be always on.
- Validating inputs and outputs of code units as well as intermediary values. Assuming valid inputs, these serve to ensure the correctness of our code. We should be able to disable these, especially in production.
We can talk about a third use case that falls somewhere in between; validating functions passed as inputs. This does not fall into the first category because functions are opaque, we cannot be sure of what kind of value they will return until we call them. It does not fall into the second category either because the function in question is external input. Validating the return values of such calls to third party functions allow us to provide helpful error messages to the consumer if the function does not satisfy the contract. Otherwise the error will occur somewhere within our code and all we can say is “here is a stacktrace, open the source now, good luck figuring out what went wrong”. Checks of this third category should be always on, like the first category.
Talk Is Cheap, Show Me the Code
Code is here. You can clone the repository and a lein run will create the following in target directory:
- results.edn contains raw results. The data is a simplified version of criterium’s output map. See validation-benchmark.core/summarize.
- chart.png shows mean run times. The tests are grouped. See resources/tests.edn.
- Criterium output is redirected to criterium.output.
Currently there is a validation-benchmark.core/quick? var that determines whether benchmark or quick-benchmark is used. Ideally it should be a command line parameter. Please make sure you set it as false before you run tests for the time being.
Currently there are few benchmarks and few libraries. For what it’s worth here are the results:
+------------------------------------+-----------+------------+
| Test name | Library | Mean (ns) |
+------------------------------------+-----------+------------+
| [:nil-allowed :valid] | :annotate | 1747.448 |
| [:nil-allowed :valid] | :herbert | 16809.820 |
| [:nil-allowed :valid] | :schema | 5640.546 |
| [:nil-allowed :invalid] | :annotate | 15178.604 |
| [:nil-allowed :invalid] | :herbert | 29018.129 |
| [:nil-allowed :invalid] | :schema | 112353.285 |
| [:sequential-collections :valid] | :annotate | 3539.017 |
| [:sequential-collections :valid] | :herbert | 35712.639 |
| [:sequential-collections :valid] | :schema | 6065.441 |
| [:sequential-collections :invalid] | :annotate | 2009.663 |
| [:sequential-collections :invalid] | :herbert | 12614.990 |
| [:sequential-collections :invalid] | :schema | 33973.530 |
+------------------------------------+-----------+------------+
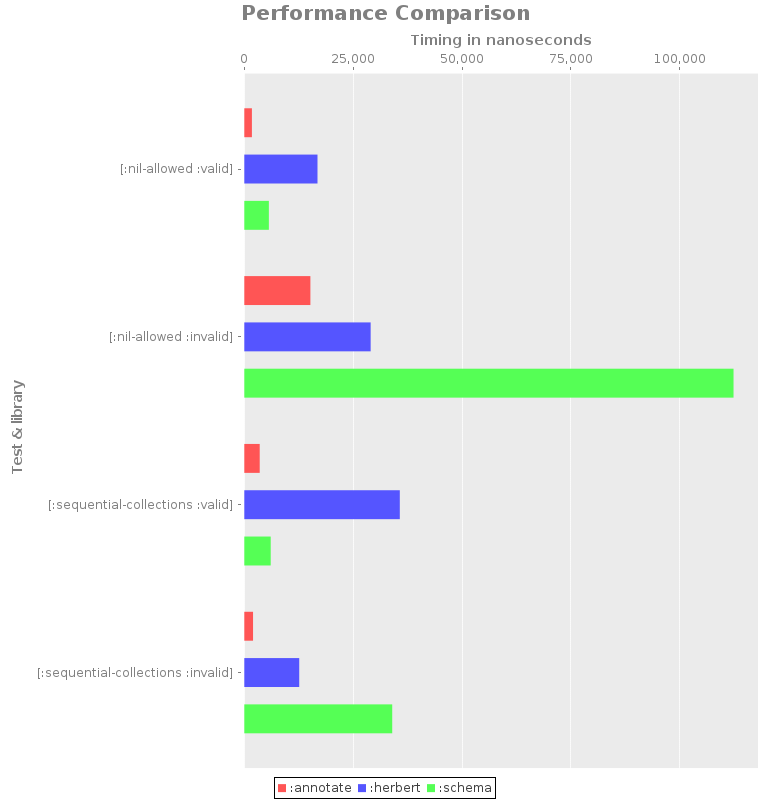
This is a better benchmark than the last one. It is far from telling us the library with the best performance. Raw results are here Please consider these results work in progress.
What Is Missing
- Currently the biggest issue is the lack of more benchmarks. Measuring some aspects of validation but not others would result in a biased conclusion. Moreover what it measures now is the simplest cases. I am especially interested in how fast complex schemas can be validated. Thanks to persistent data structures, working with large data objects is convenient and common in Clojure. (#1)
- More validation libraries. ‘Nuff said. (#2)
- If one or more benchmarks for a library are missing for a group, the results are reported wrongly, in favor of that library. This is a bug. That library should not participate in that group at all. (#3)
- School project grade code should be refactored into a more presentable state. quick? should be a command line parameter, and false by default. A lein run should be enough to run the benchmark. Also a --reuse option is useful to skip running the benchmark and just use an existing results.edn, for development. (#4)
I have created tickets for each item and linked them above. Feel free to tackle them yourself or add your commentary. I would especially appreciate if you can take a look at the code and let me know if there are any issues with the benchmarking logic.
| [1] | Just to be clear, not all new def forms are bad. For example test.check’s defspec is defining a completely new def form. It does not add generative testing capabilities to deftest. It does not even call/use deftest under the hood. |
If you have any questions, suggestions or corrections feel free to drop me a line.